Nginx monitoring with okmeter
Если вы используете nginx как reverse-proxy или для отдачи статики, okmeter поможет вам быть в курсе всего, что происходит с вашим веб-приложением.
Установленный на сервер okmeter агент автоматически найдет запущенный nginx и начнет его мониторить. Для этого агент прочитает его конфиг-файл, найдет все access логи, поймет их формат и начнет их анализировать.
Если окажется, что данный формат лога невозможно распарсить или в формате нет нужных переменных, сработает специальный триггер (без уведомления). Например, формат лога по-умолчанию не включает в себя достаточно важные переменные:
- $request_time — время ответа nginx на запрос клиента, включая передачу ответа
- $upstream_response_time — время ответа бэкенда (если в ходе клиентского запроса один из бэкендов вернул ошибку и nginx повторял запрос на другой сервер, в этой переменной будет отражено несколько значений)
- $upstream_cache_status — статус, показывающий был ли использован кэш для ответа на запрос
Все лог-файлы nginx анализируются отдельно, полученные метрики привязаны к конкретному файлу с помощью метки file, в которой содержится путь данного лога.
Наш агент также пытается собрать метрики в разрезе урлов, но предварительно сгруппировав их. Все метрики имеют метку url, в которой содержится либо непосредственно url либо специальное значение “~other”, если url не входит в топ по частоте обращений. В ходе группировки урлов из url отбрасываются аргументы и некоторые части пути заменяются на плейсхолдеры ($id, $hash, $uuid).
C одной стороны агент собирает достаточно простые метрики, но каждая из них имеет много параметров (меток), по которым можно фильтровать графики/алерты или по-разному их группировать. Рассмотрим, каждую метрику и посмотрим, для каких задач она может быть полезна:
- nginx.requests.rate {file:“X“, method: “M“, status: “YYY“, cache_status: “X“, url: “U“ }
-
— количество запросов в секунду для каждого сочетания данных меток.
По метрикам этого типа можно построить графики с различными группировками и фильтрами
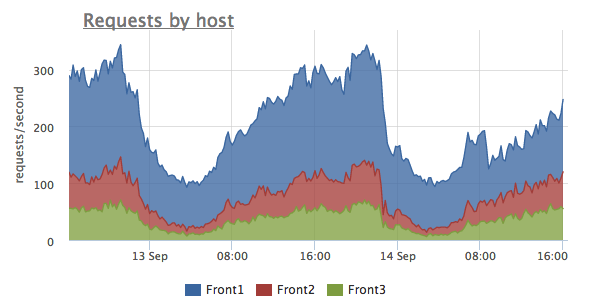 Например, на этом графике мы видим общее количество запросов и распределение запросов между серверами. На этом примере на сервер Front1 приходит больше запросов, чем на соседние серверы. Возможно в этом случае стоит разобраться с алгоритмом балансировки нагрузки.
Например, на этом графике мы видим общее количество запросов и распределение запросов между серверами. На этом примере на сервер Front1 приходит больше запросов, чем на соседние серверы. Возможно в этом случае стоит разобраться с алгоритмом балансировки нагрузки.
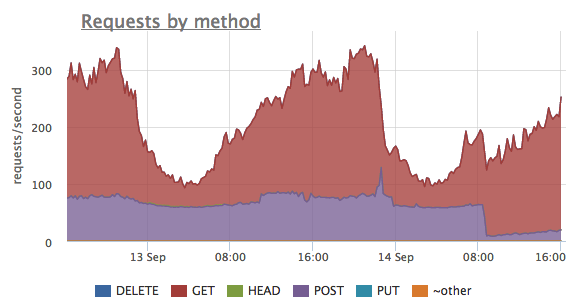 Этот график, построенный по тем же самым метрикам, показывает соотношение запросов между методами протокола HTTP. Здесь мы видим, что было достаточно много запросов с методом POST, но в какой-то момент количество этих запросов значительно упало. При этом количество GET запросов не изменилось.
Этот график, построенный по тем же самым метрикам, показывает соотношение запросов между методами протокола HTTP. Здесь мы видим, что было достаточно много запросов с методом POST, но в какой-то момент количество этих запросов значительно упало. При этом количество GET запросов не изменилось.
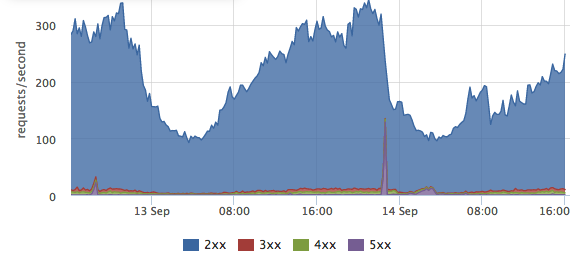 Так как в метрике есть метка со статусом ответа клиенту (status), мы можем увидеть соотношение успешных запросов (http-2xx), редиректов (http-3xx), клиентских ошибок (http-4xx) и серверных ошибок (http-5xx).
Так как в метрике есть метка со статусом ответа клиенту (status), мы можем увидеть соотношение успешных запросов (http-2xx), редиректов (http-3xx), клиентских ошибок (http-4xx) и серверных ошибок (http-5xx).
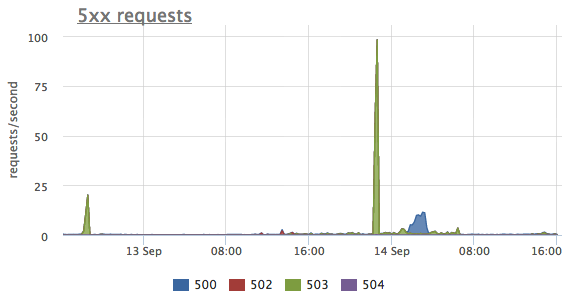 Можно выбрать только метрики запросов, завершившихся серверной ошибкой и можно посмотреть распределение между конкретными статусами. На этом графике мы видим 3 пика ошибок, в первых двух случаях сервер отвечал статусом http-503 (service unavailable), а в последнем http-500 (internal server error).
Можно выбрать только метрики запросов, завершившихся серверной ошибкой и можно посмотреть распределение между конкретными статусами. На этом графике мы видим 3 пика ошибок, в первых двух случаях сервер отвечал статусом http-503 (service unavailable), а в последнем http-500 (internal server error).
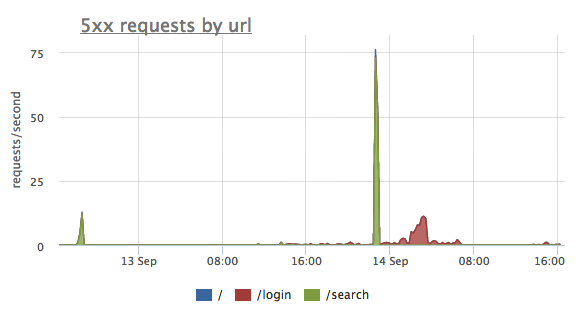 Те же самые ошибки можно сгруппировать по URL. На этом графике мы видим, что первые 2 всплеска ошибок были на странице "/search", в последнем случае были проблемы c “/login”
Те же самые ошибки можно сгруппировать по URL. На этом графике мы видим, что первые 2 всплеска ошибок были на странице "/search", в последнем случае были проблемы c “/login”
- nginx.traffic.rate {file: “X“, url=“U“ }
-
- исходящий трафик по направлению к клиенту в байтах в секунду с разбивкой по url и логу.
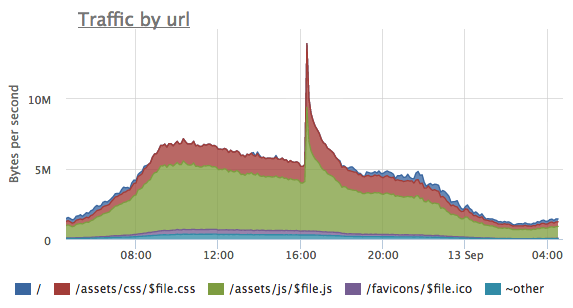
По данной метрике удобно оценивать, какие URL генерируют больше трафика и наблюдать за изменениями профиля трафика при оптимизации размера статического контента, после установки правильных заголовков кэширования или наоборот при инвалидации кэша при выходе новой версии статики.
- nginx.response_time.histogram {file: “X“, method: “M“, status: “YYY“, cache_status: “X“, url: “U“, level: “L“ }
- - гистограмма времени ответа сервера клиенту (количество запросов в секунду с разными диапазонами времени ответа). Диапазон времени ответа содержится в метке level (0-500ms, 500ms-1s, 1s+).
- nginx.upstream_response_time.histogram {file: “X“, method: “M“, status: “YYY“, cache_status: “X“, url: “U“, level: “L“ }
- - гистограмма времени ответа бэкенда. Если в метрике nginx.response_time.histogram учтено и время ответа бэкенда и время доставки ответа непосредственно до клиента, то в этой метрике содержится только распределение времени ответа бэкенда.
По гистограммам хорошо видно, работает ваш сайт как обычно или медленнее. На данном графике зеленым цветом показаны запросы, которые выполняются быстрее 500 миллисекунд, желтым - запросы, выполняющиеся от 500мс до секунды, красным - запросы, которые выполняются дольше секунды
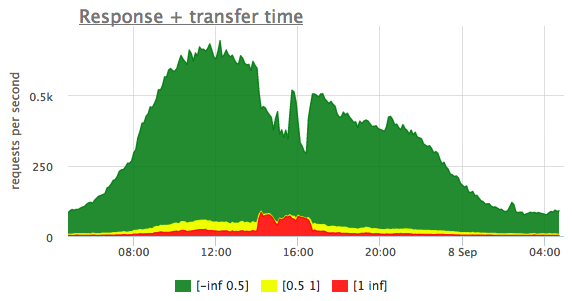
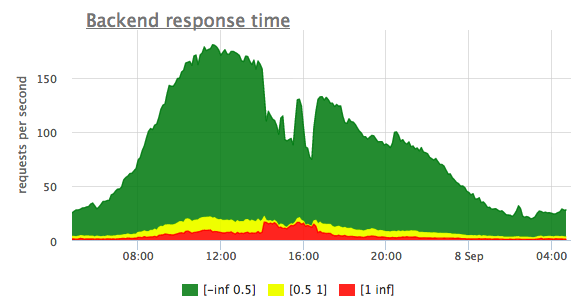
Так как на гистограмме времени ответа бэкенда "медленные" запросы тоже присутствуют, мы можем сделать вывод, что в данном случае тормозит именно бэкенд, а не канал до пользователя. На этих гистограммах запросов, доходящих до бэкенда меньше, чем суммарное количество запросов. Дело в том, что часть запросов nginx обрабатывает без участия бэкенда, например статические файлы с диска или динамические страницы из кэша.
Рассмотренные метрики, полученные из логов nginx позволяют с высокой точностью оценить, насколько хорошо работает ваш сайт (скорость работы, ошибки) на реальных пользовательских запросах, а не на синтетических запросах от системы мониторинга.