Sphinx monitoring with okmeter
Sphinx — система полнотекстового поиска с открытым исходным кодом.
Okmeter поможет вам мониторить Sphinx, чтобы с ним всегда было все в порядке.
Если на вашем сервере запущен сервис sphinx, агент okmeter автоматически определит параметры доступа к нему и начнет снимать следующие подробные метрики:
- sphinx.query.count {query_type: “local|distributed”, instance: “Y”, source_hostname: “Z”}
-
— количество обработанных запросов c момента старта сервиса с разбивкой по типу - локальные и распределенные. По данным метрикам легко оценить соотношение количества обращений к distributed и local индексам, распределение нагрузки по кластеру и всплески в количестве обращений к сервису:
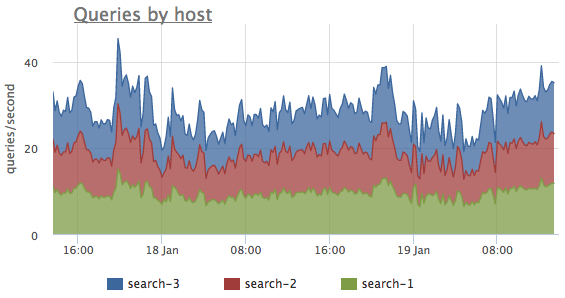
- sphinx.query.total_time {query_type: “local|distributed”, instance: “Y”, source_hostname: “Z”}
-
— суммарное время обработки запросов к сервису. По графику производной этой метрики сразу понятно, какие экземпляры сервиса на каких серверах наиболее нагружены. В случае, если индексы помещаются в память, то сервис не будет обращаться к дискам, и тогда это время будет совпадать с потреблением CPU процессом Sphinx - searchd:
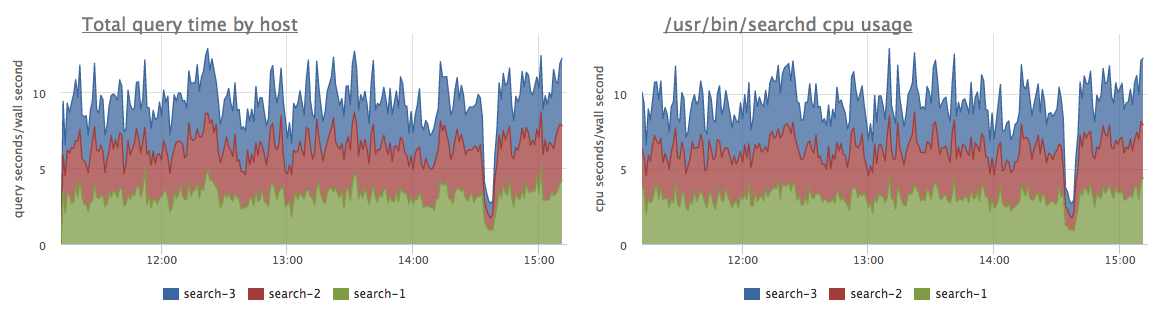 А если эти графики не совпадают, это признак того, что Сфинксу не хватает памяти для всех индексов.
Если производную
А если эти графики не совпадают, это признак того, что Сфинксу не хватает памяти для всех индексов.
Если производную sphinx.query.total_timeразделить наsphinx.query.count, получим среднее время выполнения поисковых запросов, и по такому графику хорошо видно, если с сервисом что-то не так.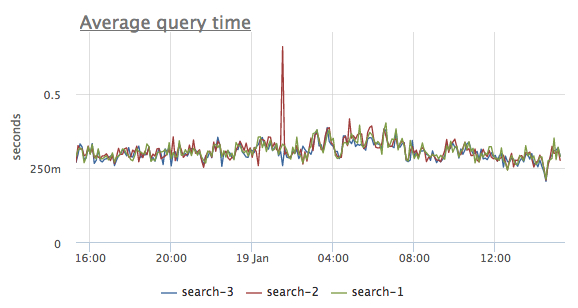
- sphinx.query.time {query_type: “local|distributed”, "stage": "cpu|disk_read|wait", instance: “Y”, source_hostname: “Z”}
-
— кумулятивная сумма времени выполнения различных стадий обработки запросов. Для запросов типа
localвозможны стадииcpuиdisk_read, но они вычисляются только если searchd запущен с аргументами--iostats --cpustats(документация). - sphinx.query.disk.ops.read {query_type: “local”, instance: “Y”, source_hostname: “Z”}
-
— кумулятивная сумма количества операций чтения с диска в процессе обработки поисковых запросов. Данная метрика доступна, если searchd запущен с аргументам
--iostats(документация). По этой метрике можно оценить соответствие производительности дисковой подсистемы текущему профилю нагрузки поиска. - sphinx.index.memory.used {index: “x”, instance: “Y”, source_hostname: “Z”}
-
— объем памяти, занимаемой каждым индексом. Можно наглядно оценить соотношение памяти для разных индексов:
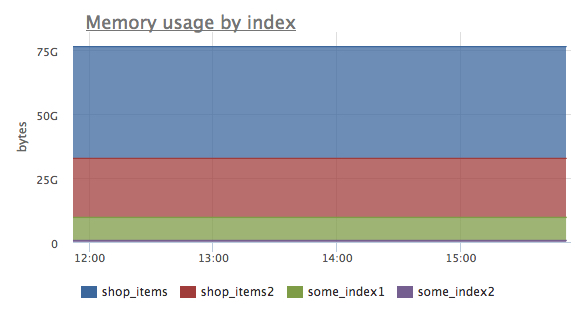
- sphinx.index.disk.used {index: “x”, instance: “Y”, source_hostname: “Z”}
- — объем диска занимаемый каждым индексом.
- sphinx.index.documents.count {index: “x”, instance: “Y”, source_hostname: “Z”}
- - количество документов в каждом индексе.
- sphinx.index.documents.bytes {index: “x”, instance: “Y”, source_hostname: “Z”}
- — сумма размеров всех исходных документов для каждого индекса.
- sphinx.uptime {instance: “Y”, source_hostname: “Z”}
- — количество секунд, прошедшее с момента старта searchd. По этой метрике удобно отслеживать перезапуск sphinx, например в моменты переконфигурации.
- sphinx.connections.count {instance: “Y”, source_hostname: “Z”}
- — текущее количество входящих соединений со Sphinx.
- sphinx.connections.overflows {instance: “Y”, source_hostname: “Z”}
- — счетчик событий достижения лимита одновременных соединений sphinx. Если данная метрика постоянно растет, значит какие-то клиенты получают ошибки при обращении к сервису. В таком случае возможно стоит увеличить лимит одновременных соединений.
Так как на одном сервере может работать несколько процессов searchd, все метрики помимо метки source_hostname имеют еще и метку instance. Если searchd работает вне контейнера, то в метку instance проставляется IP:PORT соответствующего listen сокета. А если Sphinx запущен в контейнере, то метка instance будет содержать имя этого контейнера.
Агент okmeter самостоятельно соберет все эти метрики Sphinx. Okmeter показывает детальную картину состояния вашего кластера sphinx, чтобы вы были готовы к любой ситуации.